DiffusionGemma: 4 Kat Daha Hızlı Text Generation ile Diffusion Devri Başlıyor
Google DeepMind, klasik autoregressive yapıyı terk eden DiffusionGemma'yı duyurdu. 256 tokenı aynı anda üreten bu 26B MoE model, lokal GPU'larda 4 kata varan hız artışı sunuyor. Unsloth ile 16GB VRAM'de çalıştırma rehberi ve Sudoku fine-tuning örneği.

DiffusionGemma: 4 Kat Daha Hızlı Text Generation ile Diffusion Devri Başlıyor
Büyük dil modelleri (Large Language Models, LLM) son yıllarda yazılım geliştirme, akademik araştırma ve günlük iş akışlarının ayrılmaz bir parçası oldu. Ancak bu modellerin temelinde yatan autoregressive mimari, kelime kelime ilerleyen bir daktilo mantığıyla çalışıyor. Her token, bir öncekini bekliyor. Bu sıralı yapı, özellikle uzun çıktılar üretirken gecikme (latency) sorununu kaçınılmaz kılıyor. Yani model ne kadar büyük olursa olsun, çıktı üretme hızı belirli bir fiziksel sınırda tıkanıyor.
Bu yazıda Google DeepMind'ın DiffusionGemma modelini inceliyoruz. Klasik autoregressive yapıyı terk ederek diffusion (yayılım) mekanizmasını metin üretimine taşıyan bu açık kaynak model, 256 tokenı aynı anda üretebiliyor. 26B Mixture of Experts (MoE) mimarisine sahip DiffusionGemma, lokal GPU'larda 4 kata varan hız artışı vaat ediyor. Ayrıca Unsloth ile 16GB VRAM'de çalıştırma rehberini ve Google'ın Sudoku fine-tuning örneğini de ele alacağız.
Diffusion Nedir ve Neden Şimdi Metin Üretimine Geliyor?
Diffusion teknolojisi, Stable Diffusion ve DALL-E gibi görsel üretim modelleriyle tanıdık bir kavram. Bu modeller, gürültü (noise) içeren bir kanvas üzerinden iteratif adımlarla net bir görsel ortaya çıkarıyor. Google DeepMind araştırmacıları Brendan O'Donoghue ve Sebastian Flennerhag, bu prensibi metin dünyasına taşımayı başardı.
DiffusionGemma'nın çalışma prensibi şöyle özetlenebilir:
- Kanvas oluşturma: Model, 256 token uzunluğunda rastgele yer tutucu (placeholder) tokenlarla bir kanvas başlatıyor.
- Iteratif arındırma (denoising): Birden fazla geçişte, doğru tokenlar sabitleniyor ve bu sabitlenmiş tokenlar bağlam (context) olarak kullanılarak geri kalan tokenlar iyileştiriliyor.
- Son rötuş: Tüm kanvas yüksek kaliteli, tutarlı bir metne dönüşüyor.
Google blog yazısındaki güzel bir benzetmeyle söylemek gerekirse, bu model tek sıralı daktilodan devasa bir matbaaya geçişi temsil ediyor. Tüm metin bloğu aynı anda basılıyor, kelime kelime beklenmiyor. Bu paralel yapı, özellikle düşük batch boyutlarında ve tek bir GPU üzerinde çalışırken belirgin bir hız avantajı sağlıyor.
DiffusionGemma'nın en ilginç özelliklerinden biri, çift yönlü attention (bidirectional attention) mekanizması. Autoregressive modellerde her token sadece kendinden öncekilere bakabiliyor. DiffusionGemma'da ise 256 tokenlık blok içindeki her token, diğer tüm tokenlara erişebiliyor. Bu yapı, kod tamamlama (code infilling), matematiksel grafikler, amino asit dizileri ve hatta Sudoku gibi her tokenın gelecekteki tokenlara bağlı olduğu görevlerde doğal bir üstünlük sağlıyor.
DiffusionGemma'nın Teknik Mimarisi
DiffusionGemma, Gemma 4 ailesinin MoE mimarisi üzerine inşa edilmiş. Modelin teknik özellikleri oldukça etkileyici:
- Toplam parametre: 26B (25.2B)
- Aktif parametre: 3.8B (inference sırasında)
- Expert sayısı: 128 toplam, 8 aktif + 1 paylaşımlı
- Katman sayısı: 30
- Context uzunluğu: 256K token
- Kanvas uzunluğu: 256 token
- Sliding window: 1024 token
- Vocab boyutu: 262K
- Vision encoder: Yaklaşık 550M parametre
- Desteklenen modaliteler: Metin, görsel, video (kareler)
- Lisans: Apache 2.0
Modelin mimarisi encoder-decoder yapısında. Autoregressive encoder, prompt'un KV (key-value) önbelleğini oluşturuyor. Decoder ise kanvas üzerinde çift yönlü attention uyguluyor ve önbellekteki context'e cross-attention ile erişiyor. Bu tasarım, MoE verimliliği ile birleşince güçlü çıkarım (reasoning) yeteneklerini düşük bellek ayak iziyle sunuyor.
DiffusionGemma, aynı zamanda çok dilli bir model. 140'ın üzerinde dili destekliyor ve bu, açık kaynak modeller arasında önemli bir fark yaratıyor. Görsel ve video girdileri de işleyebilen yapısı, onu saf metin modellerinden ayrıştırıyor.

Performans ve Benchmarklar
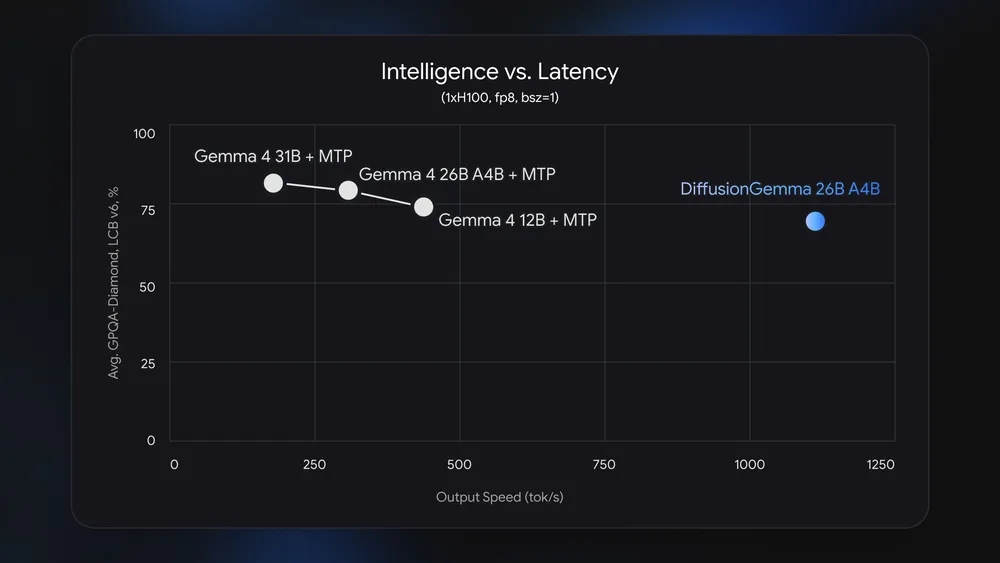
Hız, DiffusionGemma'nın en öne çıkan vaadi. Google'ın resmi verilerine göre:
- 1000+ token/saniye tek bir NVIDIA H100 üzerinde
- 700+ token/saniye NVIDIA GeForce RTX 5090 üzerinde
- 4 kata varan hız artışı autoregressive Gemma 4 ile karşılaştırıldığında
Bu hız artışının arkasındaki teknik neden, bellek bant genişliği (memory bandwidth) darboğazını hesaplama (compute) yoğunluğuna dönüştürmek. Autoregressive modellerde her token üretimi bellek bant genişliğiyle sınırlı. DiffusionGemma ise 256 tokenı paralel işlediği için GPU'nun hesaplama kapasitesini daha verimli kullanıyor. Ancak bu optimizasyon düşük batch boyutları ve tek GPU senaryolarında geçerli. Bulut ortamında binlerce isteği aynı anda işleyen yüksek batch senaryolarında, artık getirileri (diminishing returns) azalıyor.
Kalite açısından bakıldığında ise DiffusionGemma, autoregressive Gemma 4'ün gerisinde kalıyor. Bu, hız ve kalite arasındaki bilinen takas (trade-off) ilişkisini doğruluyor:
- MMLU Pro: 77.6% (Gemma 4: 82.6%)
- AIME 2026 (no tools): 69.1% (Gemma 4: 88.3%)
- LiveCodeBench v6: 69.1% (Gemma 4: 77.1%)
- GPQA Diamond: 73.2% (Gemma 4: 82.3%)
- BigBench Extra Hard: 47.6% (Gemma 4: 64.8%)
- MMMLU: 81.5% (Gemma 4: 86.3%)
- HLE (no tools): 11.0% (Gemma 4: 8.7%). Bu testte DiffusionGemma önde.
Görsel benchmarklarda da fark benzer şekilde devam ediyor. MMMU Pro testinde DiffusionGemma 54.3% elde ederken, Gemma 4 73.8% yapıyor. OmniDocBench düzen mesafesi (edit distance) testinde ise düşük skor daha iyi olduğu için Gemma 4 0.149 ile DiffusionGemma'nın 0.319 skorunu geride bırakıyor.
Bu veriler, DiffusionGemma'nın henüz deneysel bir model olduğunu ve üretim ortamlarındaki autoregressive modellerin yerini hemen almayacağını gösteriyor. Ancak interaktif, gerçek zamanlı uygulamalar için sunduğu hız avantajı, onu lokal kullanım ve hızlı prototipleme senaryolarında cazip kılıyor. Daha önce Gemma 4 ve Multi-Token Prediction yazısında ele aldığımız gibi, Google farklı hızlandırma stratejilerini aynı anda deniyor. Multi-token prediction tek bir forward pass'te birden fazla token tahmin ederken, DiffusionGemma tüm kanvası paralel olarak arındırıyor.
Unsloth ile Lokal Çalıştırma Rehberi
DiffusionGemma'yı lokal olarak çalıştırmanın en pratik yolu, Unsloth tarafından hazırlanan GGUF sürümleri ve özel llama.cpp branch'i. Bu yaklaşım, tüketici sınıfı GPU'larla bile modeli çalıştırmayı mümkün kılıyor.
Donanım Gereksinimleri
Modelin bellek ihtiyacı, kuantizasyon seviyesine göre değişiyor:
- 4-bit (Q4_K_M): Yaklaşık 16-17 GB VRAM/RAM
- 5-bit (Q5_K_M): Yaklaşık 19 GB
- 6-bit (Q6_K): Yaklaşık 23 GB
- 8-bit (Q8_0): Yaklaşık 27 GB
- BF16 (tam hassasiyet): 52 GB
Google, modelin 18 GB VRAM içine sığabileceğini belirtiyor. Bu, RTX 4090 (24 GB) ve RTX 5090 (32 GB) gibi üst segment tüketici GPU'larının rahatlıkla kaldırabileceği anlamına geliyor. 15-17 GB toplam bellek ile 4-bit kuantizasyon çalıştırılabilir. Bellek yetersizse llama.cpp, katmanları RAM veya disk'e off-load edebiliyor, ancak bu durumda üretim hızı düşüyor.
Adım Adım Kurulum
1. llama.cpp DiffusionGemma Branch'ini Derleyin
Standart llama.cpp, DiffusionGemma'yı desteklemiyor. Özel PR branch'ini kullanmak şart:
git clone https://github.com/ggml-org/llama.cpp
cd llama.cpp
gh pr checkout 24423
# veya gh CLI yoksa:
# git fetch origin pull/24423/head:diffusiongemma && git checkout diffusiongemma
# CUDA ile derle (CPU-only için -DGGML_CUDA=ON kaldır)
cmake -B build -DGGML_CUDA=ON
cmake --build build -j --config Release --target llama-diffusion-cli
Mac kullanıcıları için Metal desteği varsayılan olarak açık. Windows'ta WSL veya natif derleme mümkün.
2. GGUF Modeli İndirin
pip install -U "huggingface_hub[cli]"
hf download unsloth/diffusiongemma-26B-A4B-it-GGUF --local-dir ./diffusiongemma --include "*Q4_K_M*"
Q4_K_M yaklaşık 16 GB indirme boyutuyla en kompakt seçenek. Q8_0 ise neredeyse kayıpsız kalite sunuyor ama 27 GB civarında.
3. Sohbet Modunda Çalıştırın
./build/bin/llama-diffusion-cli -m ./diffusiongemma/diffusiongemma-26B-A4B-it-Q4_K_M.gguf -ngl 99 -cnv -n 2048
Buradaki parametreler:
-ngl 99: Tüm katmanları GPU'ya yükler (CPU-only için 0)-cnv: Çok turlu sohbet modu-n 2048: Hedef token sayısı; diffusion blok sayısını ve batch/context boyutlarını otomatik hesaplar
4. Canlı Diffusion Görselleştirmesi
llama.cpp, diffusion sürecini terminalde canlı izlemeyi mümkün kılıyor:
./build/bin/llama-diffusion-cli -m ./diffusiongemma/diffusiongemma-26B-A4B-it-Q4_K_M.gguf -ngl 99 -cnv -n 2048 --diffusion-visual
--diffusion-visual flag'i, her 256 tokenlık kanvasın adım adım nasıl arındırıldığını titreşimsiz (flicker-free) bir şekilde gösteriyor. Bu, diffusion mekanizmasını anlamak için eğitici bir deneyim.
Önerilen Inference Ayarları
Unsloth ve Google'ın ortak önerileri şöyle:
- Sampler: Entropy-Bound (EB) denoising
- Maksimum arındırma adımı: 48
- Sıcaklık (temperature) programı: Lineer azalma, 0.8'ten 0.4'e
- Entropy sınırı: 0.1
- Adaptif durdurma: Ortalama kanvas entropisi 0.005'in altına düştüğünde ve yüksek olasılıklı tokenlar 2 ardışık adımda sabit kaldığında
DiffusionGemma, Thinking Mode da destekliyor. Sistem prompt'unun başına <|think|> tokeni eklenerek dahili düşünme kanalı açılabiliyor. Model, <|channel>thought ve <channel|> etiketleri arasında düşünme sürecini, ardından nihai yanıtı üretiyor.
Lokal LLM çalıştırma konusunda daha geniş bir rehber arayanlar, daha önce yazdığım Kurumsal Şirketler İçin Local LLM Deployment rehberine göz atabilir. Orada farklı kuantizasyon stratejileri, güvenlik ve veri egemenliği konularını derinlemesine ele alıyoruz.
Unsloth Fine-tuning ile Sudoku Örneği
DiffusionGemma'nın en çarpıcı kullanım alanlarından biri, özel domain görevleri için fine-tuning. Google ve Unsloth, modelin Sudoku çözme yeteneğini kazandırmak için bir fine-tuning deneyi yaptı. Sudoku, autoregressive modeller için doğal bir zorluk teşkil ediyor çünkü her hücredeki rakam, hem aynı satır, sütun ve 3x3 karedaki diğer rakamlara bağlı. Yani her token, kendinden sonra gelen tokenlara da bağlı. Autoregressive modeller sadece sola baktığı için bu yapıyı öğrenmekte zorlanıyor.

DiffusionGemma'nın çift yönlü attention yapısı, bu problemi doğal olarak çözüyor. Fine-tuning sonrası model, Sudoku tahtasını doldurabiliyor ve hatalarını iteratif olarak düzeltebiliyor. Bu yetenek, code infilling, matematiksel ispatlar ve biyoinformatik dizilim analizleri gibi alanlarda geniş bir uygulama potansiyeline işaret ediyor.
Unsloth ile fine-tuning yapmak, modeli yaklaşık 1.5x daha hızlı ve %60 daha az VRAM ile eğitmeyi mümkün kılıyor. Unsloth, Gemma 4 ailesi için görsel, metin, ses ve RL (Reinforcement Learning) fine-tuning'ini destekliyor. DiffusionGemma için de bu destek devam ediyor. Colab, Kaggle veya lokal ortamlarda 3GB VRAM ile başlayabilirsiniz.
Fine-tuning süreci, Unsloth'un optimizasyonları sayesinde geleneksel Flash Attention 2 kurulumlarına kıyasla önemli kaynak tasarrufu sağlıyor. Bu, akademik araştırmacılar ve bağımsız geliştiriciler için demokratikleştirici bir avantaj. Daha önce Small Language Models (SLM) yazısında tartıştığımız gibi, 2026'da verimli AI gücüne olan talep artıyor. DiffusionGemma, bu trende hız ve bellek verimliliği açısından yeni bir boyut ekliyor.
Trade-off'lar ve Sınırlamalar
DiffusionGemma'yı değerlendirirken, hız ve kalite arasındaki takasın yanı sıra bazı teknik sınırlamaları da göz önünde bulundurmak gerekiyor.
Apple Silicon Mac'ler için önemli bir uyarı var. Google, modelin hız artışının bellek bant genişliği yerine hesaplama yoğunluğunu kullanmasına dayandığını belirtiyor. Apple Silicon gibi unified memory mimarisine sahip cihazlar, inference sırasında genellikle bellek bant genişliği ile sınırlı. Bu nedenle, MacBook Pro veya Mac Studio gibi cihazlarda autoregressive Gemma 4'e kıyasla aynı hızlanmayı görmek mümkün olmayabilir. Hız artışı, NVIDIA GPU'lar gibi ayrık bellek ve yüksek hesaplama kapasitesine sahip hızlandırıcılarda daha belirgin.
Bulut servisleri açısından bakıldığında, DiffusionGemma yüksek QPS (queries per second) senaryolarında autoregressive modeller kadar verimli olmayabilir. Autoregressive modeller, binlerce isteği aynı anda batchleyerek (batching) bellek bant genişliğini paylaşabilir. DiffusionGemma'nın paralel yapısı ise küçük batch boyutlarında optimize edilmiş durumda. Bu, onu lokal, interaktif kullanım için ideal, ancak yüksek ölçekli bulut servisi için henüz mükemmel olmayan bir model yapıyor.
Kalite farkı da göz ardı edilemez. MMLU, AIME, LiveCodeBench ve GPQA gibi akademik benchmarklarda Gemma 4'ün gerisinde kalması, modelin henüz üretim ortamında kritik görevler için doğrudan yerine kullanılamayacağını gösteriyor. Ancak hızın önemli olduğu chatbot, kod tamamlama, canlı not alma gibi senaryolarda bu kalite farkı kabul edilebilir olabilir.
Diğer Modeller ve Yaklaşımlarla Karşılaştırma
DiffusionGemma, tek metin diffusion modeli değil. Google DeepMind, aynı zamanda Gemini Diffusion araştırma projesini yürütüyor. Bu proje, kullanıcılara metin üretiminde daha fazla kontrol, yaratıcılık ve hız sunmayı hedefliyor. DiffusionGemma, bu araştırmanın açık kaynak ve topluluk odaklı bir uzantısı olarak konumlanıyor.
Alternatif hızlandırma yaklaşımlarına baktığımızda:
- Multi-Token Prediction (MTP): Gemma 4'ün kullandığı bu teknik, tek forward pass'te 4 token tahmin ediyor. DiffusionGemma ise 256 tokenı aynı anda işliyor. MTP, autoregressive yapıyı korurken hızı artırıyor. DiffusionGemma ise yapıyı tamamen değiştiriyor.
- Speculative Decoding: Daha küçük bir taslak modelle büyük modeli hızlandırma. Bu yöntem de autoregressive temelli ve mevcut modellerle geriye uyumlu.
- Lookahead Decoding: Gelecek tokenları önceden hesaplama. Yine autoregressive çerçevede çalışıyor.
DiffusionGemma, bu listede en radikal değişikliği temsil ediyor. Token-by-token üretim paradigmasını tamamen terk ediyor. Bu radikal değişiklik, hem en büyük avantajı (paralellik) hem de en büyük riski (ekosistem uyumsuzluğu) beraberinde getiriyor. Çoğu mevcut inference motoru, prompt caching stratejisi ve deployment pipeline autoregressive modeller için tasarlanmış. DiffusionGemma için vLLM, Hugging Face Transformers, MLX ve NVIDIA NeMo gibi framework'lerde özel destek ekleniyor, ancak geniş çapta benimsenme zaman alacak.
NVIDIA, NVFP4 (4-bit floating point) kernel desteği ile Hopper ve Blackwell mimarilerinde DiffusionGemma'yı optimize ediyor. Ayrıca NVIDIA DGX Spark, DGX Station ve RTX PRO workstation'ları da resmi destek listesinde. Bu, Google'ın modeli hem tüketici hem de kurumsal pazarda konumlandırma stratejisini gösteriyor.
Sonuç: Hız mı, Kalite mi?
DiffusionGemma, büyük dil modeli dünyasında yeni bir paradigmanın habercisi. 4 kat hız artışı, autoregressive modellerin yıllardır çözemediği gecikme probleminin ciddi bir alternatifini sunuyor. Ancak bu hız, kalite pahasına geliyor. MMLU ve kod benchmarklarındaki gerileme, modelin henüz üretimdeki GPT-4, Claude veya Gemma 4'ün yerini almayacağını gösteriyor.
Modelin gerçek gücü, interaktif uygulamalarda ortaya çıkıyor. Gerçek zamanlı kod tamamlama, canlı sohbet, kod infilling ve özel domain görevleri (Sudoku, amino asit dizilimleri) için DiffusionGemma'nın çift yönlü attention ve iteratif düzeltme yetenekleri benzersiz. Unsloth ile 16 GB VRAM'de çalışabilmesi ve açık kaynak lisansı (Apache 2.0), modeli bağımsız geliştiriciler ve akademik araştırmacılar için erişilebilir kılıyor.
2026'da AI alanında iki büyük trend var: verimlilik ve hız. DiffusionGemma, her ikisine de hizmet ediyor. MoE mimarisi sayesinde sadece 3.8B aktif parametreyle 26B modelin gücünü sunuyor. Diffusion mekanizması ise hesaplama yoğunluğunu artırarak bellek bant genişliği darboğazını aşıyor. Bu iki yenilik birleşince, tek bir RTX 4090 veya 5090 ile evinizde veya stüdyonuzda 1000 token/saniye hızına yaklaşmak mümkün.
Google'ın bu modeli duyurması, açık kaynak AI ekosisteminde farklı mimari arayışlarının önemini bir kez daha vurguluyor. Transformer ve autoregressive olmak zorunda değil. Diffusion, metin dünyasına görsel üretimden transfer edilen bir fikir ve ilk sonuçlar umut verici. İlerleyen aylarda fine-tuning topluluklarının ve inference motorlarının modeli nasıl evrimleştireceğini merakla bekliyoruz.
Siz DiffusionGemma'yı denediniz mi? Lokal kurulumda yaşadığınız deneyimleri veya fine-tuning sonuçlarınızı yorumlarda paylaşın. Ayrıca X/Twitter ve LinkedIn üzerinden benimle iletişime geçebilir, blogdaki diğer AI ve yazılım içeriklerini keşfedebilirsiniz. Bir sonraki yazıda görüşmek üzere.
Bu yazı DiffusionGemma modelinin duyurusu üzerine, Google DeepMind resmi blog yazısından, Unsloth Hugging Face sayfasından ve Unsloth dokümantasyonundan derlenmiştir.
Efe Hüseyin Özkan
Yazılım Mühendisi & AI Geliştirici
Yapay zeka sistemleri, full-stack geliştirme ve ölçeklenebilir ürün mimarisi üzerine çalışıyor. Daha fazla teknik yazı için blogu takip edebilirsiniz.