LLM'leri 3 Kat Hızlandıran Multi-Token Prediction Nedir? Gemma 4, DeepSeek ve NVIDIA Karşılaştırması
Google, Gemma 4 ailesi için Multi-Token Prediction drafter'larını duyurdu. Peki MTP nedir, speculative decoding nasıl çalışır ve DeepSeek V3, Qwen3-Next, Nemotron 3 Super ile karşılaştırması nedir?

LLM'leri 3 Kat Hızlandıran Multi-Token Prediction Nedir? Gemma 4, DeepSeek ve NVIDIA Karşılaştırması
Büyük Dil Modelleri (LLM) ile çalışan her geliştiricinin en büyük şikayeti şudur: model harika cevaplar veriyor, ancak o cevabı üretmek çok uzun sürüyor. Özellikle 30 milyar parametrenin üzerindeki modellerde, tek bir token üretmek için milyarlarca parametrenin VRAM'den işlemci birimlerine taşınması gerekiyor. Bu durum, standart otoregresif üretimi bellek bant genişliği sınırlı (memory-bandwidth bound) hale getiriyor ve gecikme (latency) ciddi bir darboğaz oluşturuyor.
Bu yazıda, Google'ın Gemma 4 ailesi için duyurduğu Multi-Token Prediction (MTP) drafter'larını ele alacağız. Peki bu teknoloji nedir, speculative decoding (tahminsel çözümleme) nasıl çalışır, ve DeepSeek V3, Qwen3-Next, NVIDIA Nemotron 3 Super gibi diğer öncü modellerdeki karşılıkları nelerdir? Hemen başlayalım.
Multi-Token Prediction (MTP) Nedir?
Standart otoregresif üretimde model, her adımda sadece bir sonraki token'i tahmin eder. Yani context'e bakar, bir token üretir, onu context'e ekler, tekrar bakar, bir token daha üretir. Bu zincirleme yapı, doğal olarak seri hale gelir ve paralelleştirme imkanı sınırlıdır.
Multi-Token Prediction (MTP) ise modelin eğitimi sırasında, sadece bir sonraki token'i değil, aynı zamanda gelecekteki birden fazla token'i de tahmin etmesini isteyen bir hedef ekler. Sebastian Raschka'nın LLM Architecture Gallery'sinde açıkladığı gibi, model her pozisyonda t+1, t+2, t+3 gibi ek tahmin kafaları (prediction heads) ile daha zengin bir denetim sinyali alır.
Bu, eğitim sırasında modelin gizli durumlarının (hidden states), sadece bir sonraki token için değil, daha sonraki token'ler için de faydalı bilgiler kodlamasını teşvik eder. Yani model, uzun vadeli bir bakış açısı kazanır.
Speculative Decoding: Hızın Sırrı
MTP'nin asıl gücü, çıkarım (inference) aşamasında speculative decoding ile ortaya çıkar. Google'ın "Fast Inference from Transformers via Speculative Decoding" makalesinde tanımlanan bu yöntem, iki modelin işbirliğine dayanır:
- Hafif taslak model (draft model): Ana modelin yanında çok daha küçük ve hızlı bir model (veya modelin kendi içindeki MTP başlığı) çalışır. Bu taslak model, boşta kalan işlemci gücünü kullanarak birkaç gelecek token'i aynı anda tahmin eder.
- Ana model doğrulaması: Ağır ve yetkin ana model (örneğin Gemma 4 31B), taslak modelin önerdiği tüm token dizisini tek bir ileri geçişte (forward pass) paralel olarak doğrular.
- Kabul veya ret: Eğer ana model, taslak modelin önerileriyle aynı fikirdeyse, tüm diziyi tek seferde kabul eder. Hatta bu sırada bir ek token daha üretir. Böylece normalde bir token üretmek için harcanan sürede, birden fazla token elde edilir.
Google'ın kendi açıklamasına göre, eğer hedef model taslak modelle aynı fikirdeyse, "tek bir ileri geçişte tüm taslak dizisini kabul eder ve hatta kendi ek token'ini de üretir. Bu, uygulamanızın normalde tek bir token üretmek için harcadığı sürede, tüm taslak dizisini artı bir token çıktı olarak verebileceği anlamına gelir."
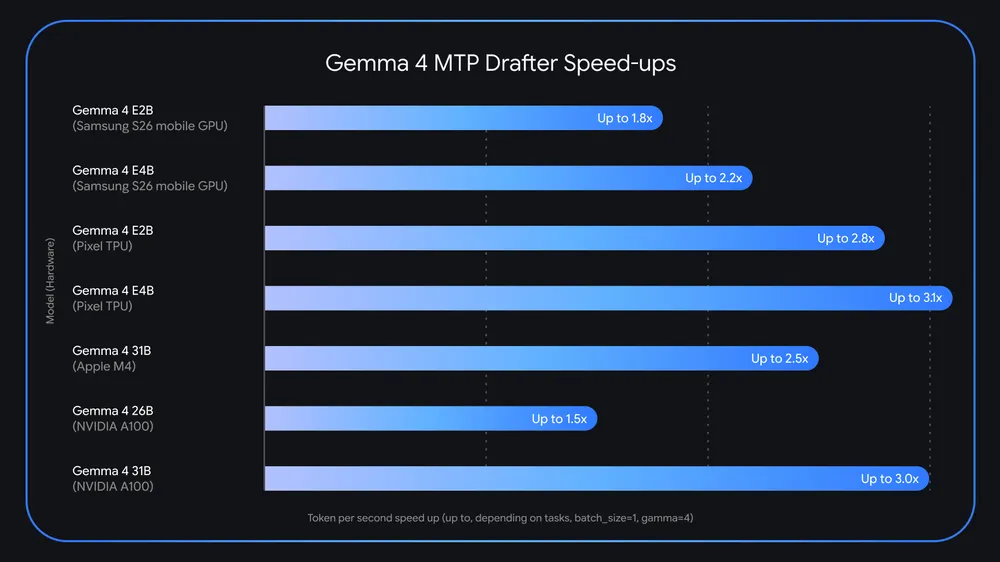
Google Gemma 4 MTP Drafters: 3x Hızlanma
Google, Mayıs 2026'da Gemma 4 ailesi için Multi-Token Prediction drafter'larını duyurdu. Bu duyuru, Gemma 4'ün 60 milyondan fazla indirilmesinin ardından geldi ve aynı Apache 2.0 açık kaynak lisansı altında sunuldu.
Gemma 4 MTP drafter'larının vaat ettiği performans rakamları şunlar:
- 3 kata kadar hızlanma: LiteRT-LM, MLX, Hugging Face Transformers ve vLLM üzerinde, çeşitli donanımlarda test edildi.
- Sıfır kalite kaybı: Ana model son doğrulama yetkisini koruduğu için, çıktı kalitesi veya muhakeme yeteneğinde herhangi bir bozulma olmuyor.
- Apple Silicon'da 2.2x hızlanma: 26B MoE modeli, batch size 4-8 kullanıldığında (batch size 1'e kıyasla) bu oranda hızlandı.
- NVIDIA A100'de benzer kazanımlar: Batch size ölçeklendirmesi büyük GPU'larda da etkili.
- Yarı yarıya bekleme süresi: NVIDIA RTX PRO 6000 üzerinde Gemma 4 26B için, aynı çıktı kalitesinde bekleme süresi yarıya indi.
Desteklenen modeller arasında Gemma 4 31B (Dense), Gemma 4 26B (MoE) ve edge cihazlar için E2B, E4B yer alıyor. Geliştiriciler Hugging Face, Kaggle, transformers, MLX, vLLM, SGLang ve Ollama üzerinden erişebiliyor.
Daha önce Gemma 4'ün genel yeteneklerini ele aldığımız Small Language Models yazımızda da belirttiğimiz gibi, Gemma ailesi edge cihazlardan buluta kadar geniş bir yelpazede çalışıyor. MTP drafter'lar bu esnekliği bir üst seviyeye taşıyor.
Rakipler Neler Yapıyor? MTP Ekosistemi Karşılaştırması
MTP, Gemma 4'ün özgün bir buluşu değil. Son birkaç yıldır önde gelen birçok model, farklı yaklaşımlarla multi-token prediction veya speculative decoding'i kullanıyor. İşte öne çıkanlar:
DeepSeek V3: MTP-1 ile Eğitim ve Çıkarım
DeepSeek V3, eğitim sırasında MTP-1 olarak adlandırılan yapı ile bir ek token tahmini ekliyor. Bu, modelin gizli durumlarının geleceğe yönelik daha zengin temsiller öğrenmesini sağlıyor. Çıkarım sırasında ise bu MTP modülü isteğe bağlı olarak speculative decoding için kullanılabiliyor. DeepSeek ekibi, bu yaklaşımın modelin kodlama ve matematik yeteneklerini de olumlu etkilediğini bildiriyor.
Qwen3-Next: Yüksek Kabul Oranlı MTP Modülü
Alibaba'nın Qwen ekibi, Qwen3-Next 80B-A3B modelinde MTP modülünü speculative decoding için optimize etmiş durumda. FlashQLA kernel yazımızda ele aldığımız Qwen ekibinin hızlandırma odaklı yaklaşımı, burada da kendini gösteriyor. Qwen3-Next'in MTP modülü, taslak token'lerin ana model tarafından kabul edilme oranını artırmaya odaklanıyor.
NVIDIA Nemotron 3 Super: Dahili Taslak Model
NVIDIA'nın Nemotron 3 Super 120B-A12B modeli, paylaşılan ağırlıklı MTP başlığı (shared-weight MTP head) kullanarak adeta bir dahili taslak model gibi çalışıyor. Bu, harici bir taslak modele ihtiyaç duymadan yerel speculative decoding yapabilmesi anlamına geliyor. Bu yaklaşım, dağıtım ve entegrasyon açısından oldukça pratik.
Step 3.5 Flash: Hem Eğitim Hem Çıkarım
Step 3.5 Flash 196B, MTP-3 yapılandırmasını hem eğitim hem de çıkarım sırasında kullanıyor. Bu, daha az rastlanan bir yaklaşım. MTP'nin çoğunlukla eğitim sinyali olarak kullanıldığı düşünülürse, Step'in her iki aşamada da aktif kullanımı dikkat çekici.
MiniMax M2.7, Xiaomi MiMo-V2, Tencent Hy3
Çin ekosisteminde MiniMax M2.7 230B, Xiaomi MiMo-V2-Flash 309B ve Tencent Hy3-preview gibi modeller de MTP veya benzeri çoklu token tahmin yapıları kullanıyor. Bu durum, MTP'nin artık bir lüks değil, büyük ölçekli LLM'ler için bir standart haline geldiğini gösteriyor.
| Model | MTP Yapılandırması | Kullanım Alanı |
|---|---|---|
| Gemma 4 | MTP Drafters (harici) | 3x hızlanma, açık kaynak |
| DeepSeek V3 | MTP-1 (isteğe bağlı çıkarım) | Kodlama ve matematik |
| Qwen3-Next | MTP modülü (yüksek kabul oranı) | Edge ve bulut optimizasyonu |
| Nemotron 3 Super | Shared-weight MTP head | Dahili speculative decoding |
| Step 3.5 Flash | MTP-3 (eğitim + çıkarım) | Hız ve kalite dengesi |
Gerçek Dünya Performansı ve Sınırlamalar
MTP ve speculative decoding her senaryoda aynı etkiyi göstermiyor. Nexus ekibinin değerlendirme çalışmasına göre, kabul oranı (acceptance rate) üretilen çıktının ne kadar öngörülebilir olduğuna bağlı.
Yüksek kabul oranı alanlar:
- Kod üretimi: sözdizimi (syntax) oldukça yapılandırılmıştır.
- Yapılandırılmış veri çıkarımı: JSON, CSV, şablonlu çıktılar.
- Standart metin kalıpları: sözleşme dili, tekrarlayan ifadeler.
Daha düşük kabul oranı alanlar:
- Açık uçlu diyalog ve yaratıcı yazım.
- Ağır muhakeme gerektiren zincirleme düşünme (chain-of-thought).
- Modelin zaten belirsiz olduğu adversarial girdiler.
Örneğin yapılandırılmış veri çıkarımında Gemma 4 MTP, %18 throughput artışı sağlarken, açık uçlu özetlemede bu oran %11'e düşüyor. Bazı senaryolarda konu sapma oranı (topic drift rate) hafifçe artabiliyor. Bu nedenle, MTP'yi değerlendirirken kendi kullanım alanınıza özel benchmark'lar yapmak kritik.
Teknik Altyapı: KV Cache Paylaşımı ve MoE Optimizasyonları
Gemma 4 MTP drafter'larının arkasındaki mühendislik detayları da ilgi çekici. Taslak modeller, hedef modelin aktivasyonlarını yeniden kullanıyor ve KV cache (anahtar-değer önbelleği) paylaşımı sayesinde gereksiz context yeniden hesaplamaları ortadan kalkıyor.
Özellikle E2B ve E4B gibi edge modellerinde, son logit hesaplaması darboğaz oluşturabiliyor. Google, burada kümeleme teknikleri (clustering techniques) kullanarak üretimi daha da hızlandırıyor. 26B MoE modeli için Apple Silicon üzerinde batch size 1'de benzersiz yönlendirme optimizasyonları uygulanmış durumda.
Bu teknik detaylar, MTP'nin sadece bir algoritma değil, donanım-model işbirliği gerektiren bir optimizasyon olduğunu gösteriyor.

Geliştiriciler İçin Pratik Rehber
Eğer siz de Gemma 4 MTP drafter'larını denemek istiyorsanız, işte hızlı başlangıç noktaları:
- Dokümantasyon: Google'ın resmi MTP dokümantasyonu en güncel entegrasyon rehberini sunuyor.
- Framework desteği: transformers, MLX, vLLM, SGLang, Ollama ve LiteRT-LM ile çalışıyor. Mevcut pipeline'ınıza entegre etmek için ayrı bir taslak model yönetmenize gerek kalmıyor.
- Mobil deneme: Google AI Edge Gallery uygulaması (Android ve iOS) ile edge modellerinde MTP'yi doğrudan telefonunuzda test edebilirsiniz.
- Kullanım alanı analizi: Uygulamanız kod üretimi veya yapılandırılmış çıktı ağırlıklıysa, MTP'den maksimum fayda sağlarsınız. Yaratıcı yazım veya açık uçlu sohbet ağırlıklıysa, kazanımlar daha sınırlı olabilir.
Ayrıca açık kaynak LLM dünyasının genel gidişatını merak ediyorsanız, Kimi K2.6 yazımızda ele aldığımız gibi, 2026'da açık kaynak modelleri kapalı kaynak devlerine ciddi şekilde meydan okuyor. MTP gibi hızlandırma teknikleri, bu rekabetin önemli bir parçası.
Sonuç: Hız Aynı Zamanda Erişilebilirliktir
Multi-Token Prediction, LLM'lerin en büyük pratik sorunlarından biri olan gecikmeyi, kaliteden ödün vermeden çözmeye aday bir teknik. Google'ın Gemma 4 MTP drafter'ları, 3 kata kadar hızlanma vaadiyle ve Apache 2.0 lisansıyla bu teknolojiyi herkesin erişimine açıyor.
Ancak MTP'nin bir sihirli değnek olmadığını da unutmamak gerek. Kullanım alanına göre değişen performans, doğru benchmark'lar ve gerçek dünya testleriyle değerlendirilmeli. Kodlama, yapılandırılmış veri işleme ve ajanik iş akışları için MTP neredeyse bir zorunluluk haline gelirken, yaratıcı uygulamalarda daha ılımlı kazanımlar sunuyor.
Sonuç olarak, speculative decoding ve MTP artık büyük ölçekli LLM'lerin standart bir parçası. Geliştiriciler olarak, bu araçları doğru yerde ve doğru şekilde kullanmak, kullanıcı deneyimini doğrudan etkileyecek. Siz Gemma 4 MTP drafter'larını denediniz mi? Deneyimlerinizi yorumlarda paylaşabilir veya benimle iletişime geçebilirsiniz.
Kaynaklar:
- Google Blog: Multi-Token Prediction in Gemma 4
- Leviathan et al., Fast Inference from Transformers via Speculative Decoding
- Gloeckle et al., Better & Faster Large Language Models via Multi-token Prediction
- Sebastian Raschka: Multi-Token Prediction
- Google AI: Gemma MTP Dokümantasyonu
- Hugging Face: Gemma 4 Koleksiyonu
Efe Hüseyin Özkan
Yazılım Mühendisi & AI Geliştirici
Yapay zeka sistemleri, full-stack geliştirme ve ölçeklenebilir ürün mimarisi üzerine çalışıyor. Daha fazla teknik yazı için blogu takip edebilirsiniz.