FlashQLA: Qwen Ekibinin Linear Attention Kerneliyle Edge AI Devrimi
Qwen ekibi, TileLang üzerine inşa edilen FlashQLA ile linear attention katmanında 2-3 kata varan hızlanma sağlıyor. GDN mimarisi, otomatik context parallelism ve donanım dostu optimizasyonlarla edge cihazlarda agentic AI yeni bir evreye giriyor.

FlashQLA: Qwen Ekibinin Linear Attention Kerneliyle Edge AI Devrimi
Büyük Dil Modellerinin (LLM) performansı son yıllarda muazzam bir ivme kazandı. Ancak bu gelişimin bedeli, hesaplama maliyetindeki sürekli artış oldu. Özellikle dikkat mekanizmasının (attention) kuadratik karmaşıklığı, uzun bağlamlar (long context) ve kişisel cihazlarda çalışan ajanik sistemler için temel bir darboğaz oluşturmaya devam ediyor. Bu noktada linear attention çözümleri, klasik softmax attention'a alternatif olarak öne çıktı. Fakat bu alternatifin kendi içinde de verimlilik sorunları mevcuttu. Qwen ekibi, bu sorunu çözmek için FlashQLA adını verdiği yeni bir linear attention kernel kütüphanesini açık kaynak olarak yayınladı. Bu yazıda, FlashQLA'nın teknik altyapısını, sağladığı kazançları ve edge AI ekosistemi için taşıdığı anlamı detaylı bir şekilde inceliyoruz.
Linear Attention Neden Önemli
Klasik transformer mimarisindeki attention mekanizması, sorgu (query), anahtar (key) ve değer (value) matrislerinin çarpılmasıyla çalışır. Bu işlemin karmaşıklığı, dizin uzunluğuyla birlikte kuadratik olarak artar. Yani 4096 tokenlik bir girdi, 8192 tokenlik bir girdiye kıyasla yaklaşık dört kat daha fazla hesaplama gerektirir. Linear attention ise bu kuadratik bağımlılığı, özellikle gizli boyut (hidden dimension) üzerinden lineer bir forma indirger. Bu, teorik olarak uzun dizinlerde önemli bir hız avantajı sağlar.
Fakat teorideki bu avantaj, pratikte her zaman beklenen performansı vermez. Linear attention katmanlarının mevcut uygulamaları, özellikle Flash Linear Attention (FLA) Triton tabanlı çözümler, bazı temel verimsizlikler içeriyordu. Qwen ekibinin FlashQLA blog yazısında da vurguladığı üzere, bu verimsizlikler iki ana başlıkta toplanıyor. Birincisi, bellek bağımlı çalışma (memory-bound execution). K, V ve ara değişkenlerin sürekli olarak HBM'den okunup yazılması, hesaplama birimlerinin boş beklemesine neden oluyor. İkincisi ise düşük GPU kullanımı (low GPU utilization). SSM durum tekrarı (state recurrence), eşzamanlı çalışan thread bloklarını batch_size çarpım num_heads ile sınırlıyor. Bu durum, küçük modellerde, düşük batch boyutlarında veya Tensor Parallelism (TP) uygulanan senaryolarda GPU SM'lerinin büyük bölümünün atıl kalması anlamına geliyor.
FlashQLA'nın Teknik Altyapısı ve Üç Ana İnovasyonu
FlashQLA, Gated Delta Network (GDN) adı verilen attention katmanı üzerine inşa edilmiş bir kütüphanedir. GDN, Qwen3-Next, Qwen3.5 ve Qwen3.6 ailelerinde kullanılan mimarinin temel taşıdır. FlashQLA'nın sunduğu çözümler üç ana başlıkta toplanabilir. Bu başlıkları, Qwen ekibinin yayınladığı teknik blogdan alınan formüller ve açıklamalar eşliğinde ele alalım.
1. Gate-Temelli Otomatik Intra-Card Context Parallelism (AutoCP)
GDN'nin en ayırt edici özelliklerinden biri, üstel azalma (exponential decay) özelliğine sahip gate mekanizmasıdır. Bu, bir önceki durumun (state) sonraki adımlara ne ölçüde etki ettiğini kontrol eden bir katsayıdır. FlashQLA ekibi, bu özelliği kullanarak otomatik context parallelism mekanizmasını geliştirmiş. Peki bu pratikte ne anlama geliyor?
Normal şartlarda, linear attention katmanının tamamı tek bir kernel içinde birleştirilmiş (fused) olsa bile, GPU SM kullanımı düşük kalabiliyor. Çünkü SSM durum tekrarı, hesaplamayı seri hale getiriyor. FlashQLA ise hesaplamayı iki aşamaya bölüyor. Birinci aşamada, yerel (local) durumlar hesaplanıyor. İkinci aşamada ise, ranklar arası düzeltme (cross-rank correction) uygulanıyor. İşin ilginç tarafı, gate'in üstel azalma özelliği sayesinde, geçmişteki durumların etkisi belli bir noktadan sonra gürültü seviyesinin altına düşüyor. Qwen ekibinin gerçek veriler üzerinde yaptığı analizler, linear attention headlerinin yüzde 60-80'inde bu azalma katsayısının sabit 1 olmadığını gösteriyor. Bu durumda, 6-8 chunklik bir warmup periyodu başlangıç durumunu sıfırdan başlatmak, hatayı gürültü tabanının altına indiriyor.
Bu ne demek? M düzeltme matrisinin hesaplanması gerektiği durumlarda, bu matris atlanabiliyor ve çok daha hafif bir warmup işlemi yeterli oluyor. FlashQLA, çalışma zamanı modeliyle her bir CP ranki için chunk sayısını (L) otomatik olarak seçiyor. Toplam N chunk için, adım 2.1 ve 3'ün çalışma zamanı L ile orantılıyken, adım 2.2'nin çalışma zamanı N/L ile orantılı. FlashQLA, L = karekök(N) şeklinde bir optimum noktayı otomatik olarak buluyor. AutoCP'nin tetiklendiği koşullar ise şu şekilde: batch_size çarpım num_heads 40 veya daha az ise, ya da batch_size çarpım num_heads 56 veya daha az ve dizin uzunluğu 8192 veya daha fazla ise.
2. Donanım Dostu Cebirsel Reformülasyon
FlashQLA'nın ikinci büyük katkısı, GDN Chunked Prefill'in ileri (forward) ve geri (backward) geçişlerinin cebirsel yapılarının yeniden formüle edilmesidir. Qwen ekibi, mevcut FLA implementasyonundaki hesaplama adımlarını analiz ederek, Tensor Core, CUDA Core ve SFU (Special Function Unit) üzerindeki yükü azaltmış. Bunu yaparken sayısal hassasiyetten ödün verilmemiş.
Basitçe ifade etmek gerekirse, mevcut implementasyonda bağımsız kernel'lere bölünmüş hesaplama adımları, FlashQLA'da yeniden düzenlenmiş. A matrisinin hesaplanması, ardından W ve U değişkenlerinin çıkarılması, daha sonra V düzeltmesi ve nihai çıktı (O) üretimi gibi adımlar, donanımın paralel işlem yeteneklerine daha uygun bir şekilde yapılandırılmış. Bu reformülasyon, bellek trafiğini azaltmanın yanında, Tensor Core'ların matris çarpma yeteneklerini daha verimli kullanmayı sağlıyor.
3. TileLang Üzerine İnşa Edilmiş Warp Özelleşmiş Kernel'ler
FlashQLA'nın üçüncü ve belki de en teknik inovasyonu, TileLang çerçevesi üzerine inşa edilmiş olmasıdır. TileLang, GPU kernel optimizasyonu için tasarlanmış bir DSL (Domain Specific Language) ve derleyici altyapısıdır. FlashQLA ekibi, hesaplamanın tamamını tek bir devasa kernel içinde birleştirmek yerine, context parallelism ve backward geçiş gereksinimlerini göz önünde bulundurarak birkaç kritik fused kernel oluşturmuş.
Bu kernel'lerde, üretici/tüketici warp grubu özelleşmesi (producer/consumer warpgroup specialization) kullanılarak veri hareketi, Tensor Core hesaplaması ve CUDA Core hesaplaması üst üste bindiriliyor (overlap). Yani bir warp grubu bellekten veri getirirken, diğeri önceki veri üzerinde hesaplama yapabiliyor. Bu teknik, kernel fisyonunun (fusion) sağladığı bellek bant genişliği kazanımlarını korurken, paralelliği artırmayı mümkün kılıyor.
Benchmark Sonuçları ve Performans Kazanımları
FlashQLA'nın performansı, NVIDIA Hopper (SM90) mimarisi üzerinde FLA Triton ve FlashInfer baseline'larıyla karşılaştırıldı. Testlerde Qwen3.5 ve Qwen3.6 ailelerinin kullandığı head konfigürasyonları (h_k,v elemanları {64, 48, 32, 24, 16, 8}, yani TP1'den TP8'e kadar) kullanıldı.
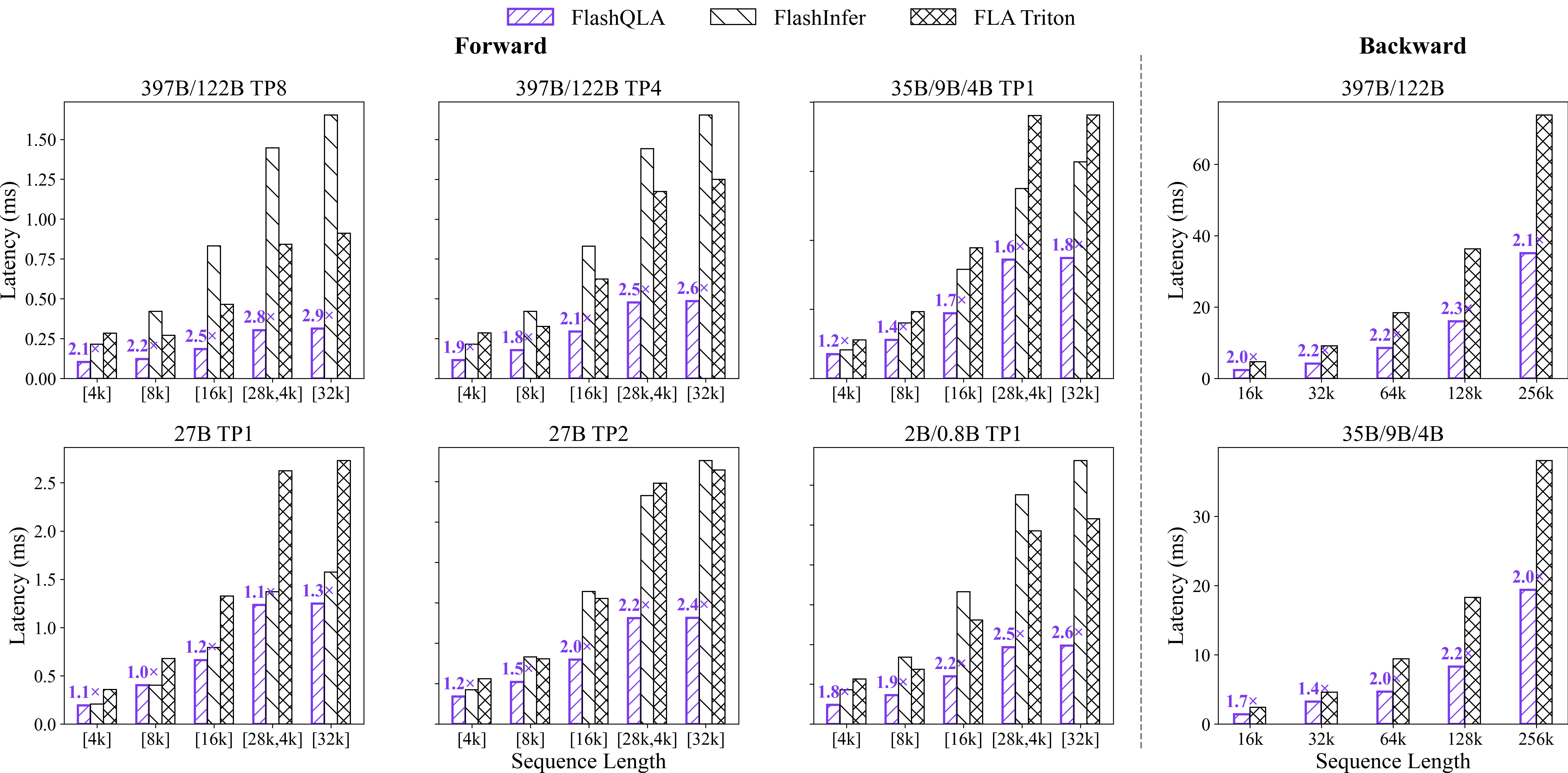
Sonuçlar oldukça etkileyici. İleri geçişte (forward pass) 2 ile 3 kat arası hızlanma sağlanmış. Geri geçişte (backward pass) ise 2 kat hızlanma elde edilmiş. Bu kazanımlar, farklı model boyutlarında ve TP ayarlarında, değişken batch uzunluklarında tutarlı bir şekilde gözlemlenmiş. Özellikle ön eğitim (pretraining) senaryolarında ve küçük modellerde, bu hızlanma daha da belirgin hale geliyor.
Qwen ekibinin teknik blogunda belirttiği üzere, FlashQLA'nın en dikkat çekici başarısı küçük modellerde ve uzun bağlamlı çalışmalarda ortaya çıkıyor. İşte tam da bu noktada, edge cihazlarda çalışan ajanik sistemler için büyük bir umut ışığı doğuyor.
Edge AI ve Agentic Sistemler İçin Ne İfade Ediyor
FlashQLA'nın çıkışı, yerel AI ve ajanik sistemler alanında önemli bir kilometre taşıdır. Geliştiriciler olarak biliyoruz ki, kişisel bilgisayarlarda veya mobil cihazlarda çalışan güçlü ajanlar, donanım kısıtları yüzünden genellikle küçük modellere mahkum kalıyor. Bu küçük modeller ise, attention katmanlarının verimsizliği nedeniyle uzun bağlamları işlemekte zorlanıyor.
FlashQLA ile birlikte, bu durum değişmeye başlıyor. İleri geçişte 2-3 kat, geri geçişte 2 kat hızlanma, demek ki aynı donanım üzerinde daha büyük bağlamlar işleyebilmek, ya da aynı bağlam uzunluğunda daha hızlı yanıtlar alabilmek mümkün. Bu, Small Language Modellerin edge cihazlardaki potansiyelini bir üst seviyeye taşıyor. Gemma 4 ve Qwen 3.6 gibi verimli modellerin yanında, FlashQLA gibi kernel seviyesinde optimizasyonlar, kişisel cihazlarda gerçek anlamda ajanik deneyimler sunmayı mümkün kılıyor.
Ayrıca, FlashQLA'nın otomatik context parallelism mekanizması, çoklu GPU ya da hatta tek GPU üzerindeki farklı SM'ler arasında iş paylaşımı yapılmasını sağlıyor. Bu, edge cihazlardaki sınırlı GPU kaynaklarının daha verimli kullanılması anlamına geliyor. Bir başka deyişle, aynı telefon ya da laptop, artık daha önce mümkün olmayan uzunluklardaki görev tanımlarını (system prompts) ve bellek bağlamlarını işleyebilecek.
Kimi K2.6 gibi modellerin ajanik kodlama yetenekleri veya Karpathy'nin autoresearch projesi gibi kendi kendine araştırma yapan sistemler düşünüldüğünde, bu tür kernel seviyesinde optimizasyonların katma değeri daha net görülüyor. Ajanik sistemler, uzun bağlamlar üzerinde sürekli çalıştıkları için, attention katmanının verimliliği doğrudan kullanıcı deneyimine yansıyor.
Kurulum ve Kullanım
FlashQLA, NVIDIA Hopper (SM90) ve üzeri mimarilerde, CUDA 12.8 ve PyTorch 2.8 üzeri sürümlerle çalışıyor. Kurulumu oldukça basit:
git clone https://github.com/QwenLM/FlashQLA.git
cd FlashQLA
pip install -v .
Yüksek seviyeli API kullanımı ise şu şekilde:
import torch
from flash_qla import chunk_gated_delta_rule
o, final_state = chunk_gated_delta_rule(
q=q, # [B, T, H_q, K]
k=k, # [B, T, H_q, K]
v=v, # [B, T, H_v, V]
g=g, # [B, T, H_v]
beta=beta, # [B, T, H_v]
scale=scale,
initial_state=initial_state,
output_final_state=True,
cu_seqlens=cu_seqlens,
)
Daha düşük seviyeli API'lerle ayrı ileri ve geri geçiş çağrıları da mümkün. Detaylar için Qwen ekibinin GitHub reposuna göz atabilirsiniz.
Sonuç ve Değerlendirme
FlashQLA, linear attention alanında önemli bir teknik ilerlemedir. Qwen ekibi, mevcut FLA Triton implementasyonunun temel verimsizliklerini tespit ederek, gate mekanizmasının üstel azalma özelliğinden yararlanan AutoCP, donanım dostu cebirsel reformülasyon ve TileLang tabanlı warp özelleşmiş kernel'lerle çözüm sunuyor. Elde edilen 2-3 kata varan hızlanma, özellikle küçük modeller ve uzun bağlamlarda, edge AI ekosistemi için kritik öneme sahip.
Geliştiriciler olarak bizim için öğrenilmesi gereken temel ders şu: Donanımın sunduğu olanakları tam olarak kullanabilmek için, algoritmik tasarımı donanım mimarisine göre optimize etmek gerekiyor. FlashQLA, bu ilkenin güzel bir uygulaması olarak öne çıkıyor. Ayrıca, TileLang gibi modern kernel DSL'lerinin, geleneksel CUDA programlamaya kıyasla ne kadar verimli olabileceğinin de bir kanıtı.
Sizler de FlashQLA'yı kendi projelerinizde denediniz mi? Edge cihazlarda çalışan ajanik uygulamalar geliştiriyor musunuz? Yorumlarda düşüncelerinizi paylaşabilirsiniz. Yeni yazılardan haberdar olmak için sitemi takip etmeyi unutmayın.
Bu yazıda kullanılan teknik detaylar, benchmark verileri ve görseller, Qwen ekibinin FlashQLA blog yazısından alınmıştır.
Efe Hüseyin Özkan
Yazılım Mühendisi & AI Geliştirici
Yapay zeka sistemleri, full-stack geliştirme ve ölçeklenebilir ürün mimarisi üzerine çalışıyor. Daha fazla teknik yazı için blogu takip edebilirsiniz.