MiniMax M3: Açık Ağırlıklı Modellerin Yeni Sınırı ve MSA Mimarisi
MiniMax M3, 1 milyon token bağlam penceresi, MSA sparse attention mimarisi, doğal çoklu-modalite ve kodlama/ajan alanında frontier performansıyla açık kaynak dünyasına yeni bir soluk getiriyor. Benchmarklar, fiyatlandırma ve gerçek dünya senaryoları bu yazıda.

MiniMax M3: Açık Ağırlıklı Modellerin Yeni Sınırı ve MSA Mimarisi
Yazılım geliştiriciler olarak son iki yıldır sürekli aynı sahneyi izliyoruz. Kapalı kaynak modellerin benchmark tabloları süpürdüğü, açık kaynak topluluğunun ise aradaki farkı kapatmaya çalıştığı bir yarış. 1 Haziran 2026'da MiniMax M3 bu dinamiği bozdu. Xiyu Technology'nin (MiniMax) açık kaynak dünyasına sunduğu yeni amiral gemisi, 1 milyon token bağlam penceresi, doğal çoklu-modalite (native multimodality) ve yepyeni bir dikkat mekanizması olan MiniMax Sparse Attention (MSA) ile geliyor. Üstelik kodlama ve ajan (agentic) görevlerde GPT-5.5 ile Gemini 3.1 Pro'yu geride bırakıp Claude Opus 4.7'ye yaklaşıyor.
Bu yazıda M3'ün mimarisini, benchmark sonuçlarını, fiyatlandırmasını, erişim yollarını ve geliştirici dünyası için gerçek anlamını ele alacağız. Lafı dolandırmadan, somut sayılarla ve örneklerle ilerleyeceğiz.

1. M3 Neden Bu Kadar Konuşuluyor?
Frontier modeller artık üç yetenek üzerinden tanımlanıyor: üst düzey kodlama, çok uzun bağlam penceresi ve doğal çoklu-modalite. Bu üçü birden bulunan açık ağırlıklı bir model şimdiye kadar yoktu. M3, bu üçünü ilk kez tek bir açık kaynak pakette buluşturuyor. Resmi MiniMax blog yazısında da vurgulandığı gibi bu üç özellik artık "table stakes", yani beklentilerin taban çizgisi haline geldi.
Kısaca M3'ün kimlik kartı:
- Çıkış tarihi: 1 Haziran 2026 (API 31 Mayıs'ta açıldı)
- Mimari: Sparse Mixture-of-Experts + MiniMax Sparse Attention (MSA)
- Bağlam penceresi: 1 milyon token (garantili 512K alt sınır)
- Modaliteler: Metin, görsel ve video giriş; metin çıkış
- Ağırlıklar: Open-weights (API'den kısa süre sonra yayında)
- En güçlü olduğu alanlar: Kodlama, ajan tabanlı araç kullanımı, uzun bağlam akıl yürütme, çoklu-modalite
M3, MiniMax'ın M2 ailesinin (M2, M2.5, M2.7) devamı olarak gözükse de aslında nesilsel bir sıçrama. M2 serisi sparse attention'ı kaldırıp full attention'a geçmişti. M3 ise sparse attention'ı yepyeni bir formda geri getiriyor. Kimi K2.6 yazımızda da bahsettiğimiz açık kaynak kodlama modelleri dalgasının en yeni halkası.
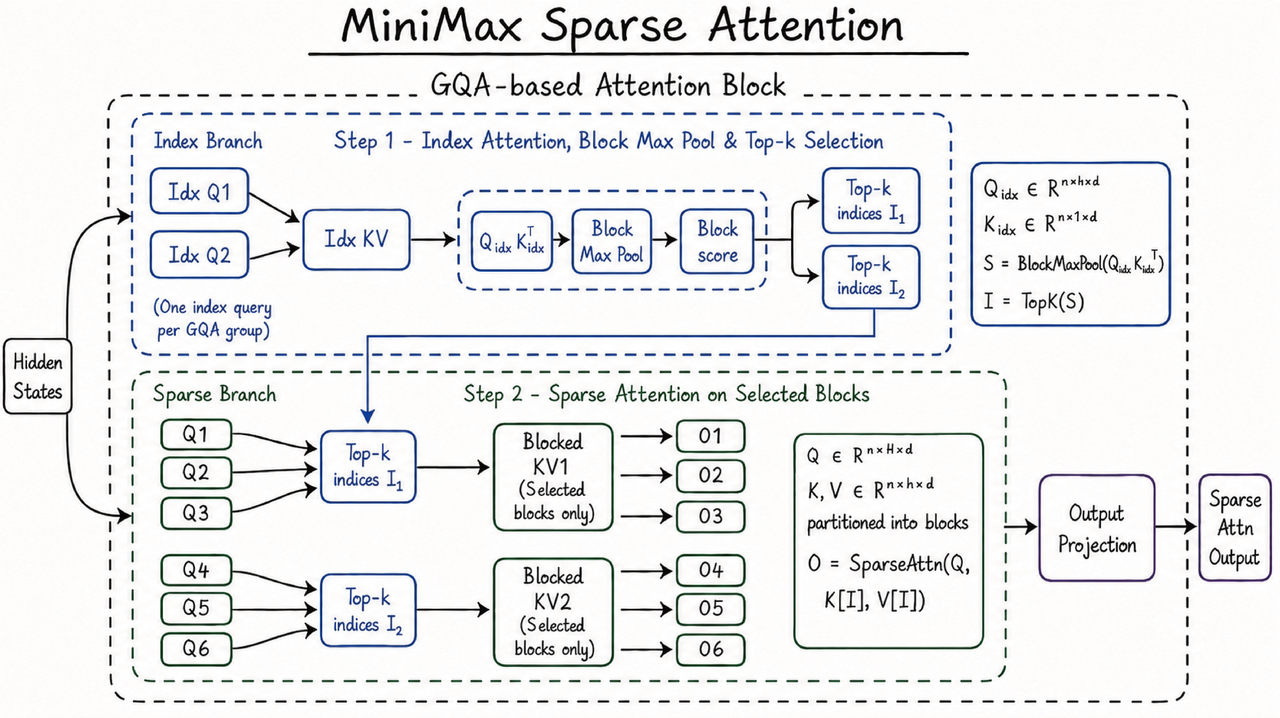
2. MSA: Sparse Attention'ın Yeni Formu
Standart transformer dikkat mekanizması karesel (quadratic) bir maliyete sahip. Her token, bağlamdaki diğer tüm tokenlara bakar. Bağlamı iki katına çıkarmak dikkat hesaplamasını dört katına çıkarır. Bu yüzden uzun bağlam pencereleri yıllardır yavaş ve pahalı kaldı. Bu sorunu sitede daha önce FlashQLA yazımızda da ele almıştık: Qwen ekibi linear attention kerneliyle edge AI'da benzer bir darboğaza çözüm arıyordu.
MSA, full attention'ı bir KV-block seçim mekanizması ile değiştiriyor. Model, her sorgu (query) için en alakalı anahtar-değer önbellek (KV cache) bloklarını seçiyor. Sonuç olarak uzun bağlamda token başına hesaplama düşerken kalite korunuyor. Resmi duyuruda belirtilen kazanımlar çarpıcı:
- ~9x daha hızlı prefill (1M token'da, bir önceki nesle göre)
- ~15x daha hızlı decoding (1M token'da, bir önceki nesle göre)
- 1M token'da token başına hesaplama sadece 1/20'si önceki modele kıyasla
- Flash-Sparse-Attention ve flash-moba'dan 4x daha hızlı operatör seviyesinde
MSA, DSA ve MoBA gibi rakiplerinden ayrılarak KV'yi bloklara daha hassas bölümlüyor. Operatör seviyesinde "KV outer gather Q" yaklaşımını benimsiyor: her blok yalnızca bir kez okunuyor, bellek erişimi sürekli, aritmetik yoğunluk önceki yöntemlere göre dramatik biçimde yüksek. Tüm bu optimizasyonlar teoride güzel görünen kazanımları pratikte de gerçek kılıyor.
3. Benchmarklar: Kodlama, Ajan ve Çokli-modalite
MiniMax M3'ün en iddialı olduğu alan kodlama. SWE-Bench Pro, Terminal-Bench 2.1, SWE-fficiency, KernelBench Hard ve MCP Atlas sonuçlarına bakalım:
- SWE-Bench Pro: %59.0 — uzun vadeli gerçek dünya yazılım mühendisliği görevleri (GPT-5.5 ve Gemini 3.1 Pro'yu geride bırakıyor, Opus 4.7'ye yaklaşıyor)
- Terminal-Bench 2.1: %66.0 — ajan tabanlı terminal ve CLI görevleri
- SWE-fficiency: %34.8 — mühendislik görevlerinin verimli çözümü
- KernelBench Hard: %28.8 — GPU kernel optimizasyonu
- MCP Atlas: %74.2 — Model Context Protocol araç kullanımı
Lushbinary'in detaylı geliştirici kılavuzunda da paylaşılan BrowseComp'ta ise M3 83.5 puan alarak Opus 4.7'nin 79.3'ünü geçiyor. OmniDocBench çoklu-modalite kıyaslamasında Gemini 3.1 Pro'nun üstüne çıkıyor. Claw-Eval'de ise uçtan uca ajan değerlendirmesinde en yüksek skoru alıyor.
Burada önemli bir parantez açalım. Satıcı yayınladığı benchmarklara her zaman sağlıklı şüpheyle yaklaşmak gerekiyor. M3'ü üretime almadan önce kendi gerçek iş yükünüze karşı bir değerlendirme seti kurmanızı öneririm. Karpathy'nin Autoresearch yazısında bahsettiğimiz değerlendirme odaklı geliştirme yaklaşımı burada da geçerli.
4. Gerçek Dünya Görevleri: 12 ve 24 Saatlik Otonom Çalışma
Benchmarklar tek başına yeterli değil. M3'ün ilginç yanı, uzun vadeli ajan görevlerindeki performansı. MiniMax ekibi üç çarpıcı gerçek dünya senaryosu paylaştı:
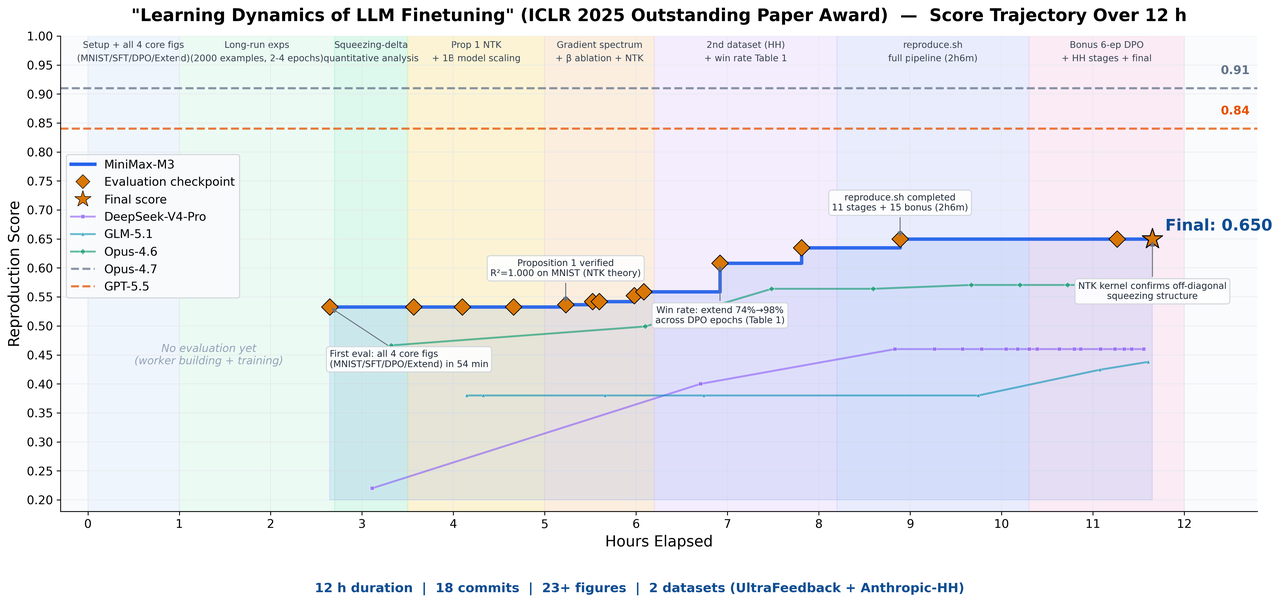
Senaryo 1: Bağımsız Makale Yeniden Üretimi. Ekip, ICLR 2025 Outstanding Paper ödüllü "Learning Dynamics of LLM Finetuning" makalesini M3'e verdi. M3, yaklaşık 12 saat boyunca otonom çalışarak 18 commit, 23 deney figürü üretti ve SFT aşamasındaki olasılık değişim trendini başarıyla eşleştirdi. DPO deneylerindeki "squeezing effect"i gözlemledi ve makalenin önerdiği Extend mitigation yöntemini doğruladı. Bunu yapabilmek için makaleyi, kodu ve deney loglarını tek seferde bağlama sığdırmak gerekiyordu.
Senaryo 2: CUDA Kernel Optimizasyonu. NVIDIA Hopper mimarisinde FP8 GEMM (General Matrix Multiplication) kerneli yazmak deneyimli bir ekip için 1-2 hafta sürer. M3'e yalnızca görev açıklaması, bir benchmark değerlendirme scripti ve çalışmayan bir Triton iskeleti verildi. Referans çözüm yoktu. Model, yaklaşık 24 saat boyunca 147 benchmark gönderimi ve 1.959 araç çağrısı yaptı. Sonunda Hopper FP8 donanım tepe kullanımını %7.6'dan %71.3'e çıkardı, 9.4x hızlanma elde etti. En iyi çözüm 145. gönderimde geldi, öncesinde birçok performans platosundan geçti. Bu, M3'ün "teslim olmayan" bir ajan olduğunu gösteriyor. Sitede daha önce ele aldığımız Zed 1.0 editör yazısında da benzer bir "akıllı araç, dayanıklı ajan" anlayışı görüyoruz.
Senaryo 3: Base Modelleri Eğitme (PostTrainBench). Ekip, yalnızca ön-eğitimden geçmiş 4 Base modeli M3'e verdi. 12 saat içinde veri sentezi, eğitim, değerlendirme ve iterasyonun tamamını insan müdahalesi olmadan yaptı. Sonuç: AIME2025, BFCL, GPQA Main, GSM8K ve HumanEval üzerinde 0.37 skor, Opus 4.7'nin (0.42) ve GPT-5.5'in (0.39) hafif altında, diğer modellerin belirgin üstünde.
5. Fiyatlandırma: Açık Kaynağın Ekonomik Avantajı
M3, OpenRouter üzerinde geçici %50 promosyon ile $0.30 / milyon input token ve $1.20 / milyon output token fiyatıyla listelendi. Standart fiyat ise $0.60 / $2.40. Karşılaştırmak için:
- M3 (promosyon): $0.30 input / $1.20 output
- M3 (standart): $0.60 input / $2.40 output
- Claude Opus 4.x: $5.00 input / $25.00 output
- GPT-5.5: ~$10.00 input / ~$30.00 output
Somut bir örnek: 500K input + 100K output token tüketen bir ajanik kodlama görevi için:
- M3 (promosyon): (0.5 × $0.30) + (0.1 × $1.20) = $0.27 görev başına
- M3 (standart): (0.5 × $0.60) + (0.1 × $2.40) = $0.54 görev başına
- Claude Opus: (0.5 × $5.00) + (0.1 × $25.00) = $5.00 görev başına
Promosyon fiyatla M3 aynı görevi Opus maliyetinin yaklaşık %5'i ile çalıştırıyor. Standart fiyatla bile onda biri. Yüksek hacimli ajanik iş yüklerinde bu fark, ürünün ekonomik olarak yapılabilir olup olmamasını belirliyor. M3, fiyat avantajıyla SLM yazımızda bahsettiğimiz verimli AI trendini üst seviyeye taşıyor.
Abonelik tarafında ise MiniMax Token Plan üç kademede geliyor: Plus ($20/ay, ~1.7B M3 token), Max ($50/ay, ~5.1B M3 token) ve Ultra ($120/ay, ~9.8B M3 token). Aynı token havuzundan metin, görsel, ses ve müzik üretimi yapılabiliyor. Bu, aynı fiyat aralığındaki rakiplerine göre dünya çapında en yüksek token kotalarından biri.
6. M3 Kod: Ajan Ürününün Kendisi de M3 ile Birlikte Eğitildi
M3 ile birlikte MiniMax Code da güncellendi. M3 ile birlikte eğitilen bu ajan ürünü, uzun bağlam ve çoklu-modalite avantajlarını tam olarak kullanıyor. Agent Team özelliği, büyük görevleri çok aşamalı, eşzamanlı ve dinamik olarak ayarlanabilir iş akışlarına bölüyor. "Producer + Verifier" adversarial döngüsüyle sürekli üretiyor, yansıtıyor ve düzeltiyor. Günlerce insan müdahalesi olmadan çalışabiliyor.
Claude Code'un Dynamic Workflows çıkışıyla benzer bir yönde ilerleyen MiniMax Code, "sabit JS orkestasyonu" yerine "derin yansıtma ve sürekli hata düzeltme"ye odaklanıyor. Native çoklu-modalite sayesinde bilgisayar kullanımı (computer use) da destekleniyor. Telefondan "Yerel ERP uygulamasını aç ve bu Excel tablosuna göre fatura bilgilerini toplu gir" diyebiliyorsunuz, M3 işlemi sizin yerinize uygulamalar arasında tamamlıyor.
İlginç olan şu: MiniMax Code, açık kaynak community projeleri OpenCode ve Pi üzerine inşa edilmiş. MiniMax bu projeyi gelecekte açık kaynak olarak yayınlamayı planlıyor. Bu, geliştirici topluluğu için çok önemli bir sinyal.
7. API ve Erişim Yolları
M3'e üç pratik yoldan ulaşabilirsiniz:
A. MiniMax Platform API: platform.minimax.io'dan API anahtarı alıp OpenAI uyumlu endpoint'i kullanabilirsiniz:
curl https://api.minimax.io/v1/chat/completions \\
-H "Authorization: Bearer $MINIM...EY" \\
-H "Content-Type: application/json" \\
-d '{
"model": "MiniMax-M3",
"messages": [
{"role": "user", "content": "Bu repoyu özetle ve refactor planı öner."}
]
}'B. OpenRouter: Promosyon fiyatla en hızlı test yolu. OpenAI uyumlu istemcinizi OpenRouter'a yönlendirip model adını "minimax/minimax-m3" yapmanız yeterli.
C. Kendi Altyapınızda Çalıştırma: Open-weights yayınlandıktan sonra vLLM veya SGLang gibi inference motorlarıyla kendi GPU kümenizde çalıştırabilirsiniz. Ancak bu yalnızca sürekli yüksek hacimde anlamlı, düşük hacimde API çok daha ucuz. Lisans ticari kullanım koşulları içeriyor, ürüne entegre etmeden önce şartları dikkatle okuyun.
API tarafında iki hizmet seviyesi var: standart tier normal istekler için, priority tier yüksek eşzamanlılık altında SLA-hassas endüstriyel kullanım senaryoları için. Priority kanal şu anda satış ekibi üzerinden açılıyor, birkaç gün içinde tüm kullanıcılara açılması bekleniyor.
8. Nerede Kullanmalı, Nerede Kullanmamalı?
M3'ün üç farklılaştırıcısı bir araya geldiğinde güçlü olduğu yerler netleşiyor:
Çok uygun olduğu senaryolar:
- Büyük repolar üzerinde uzun vadeli kodlama ajanları
- Maliyetin belirleyici olduğu yüksek hacimli ajanik iş akışları
- Tüm kod tabanı veya tüm doküman analizi
- Otonom tarama ve araştırma ajanları
- Çoklu-modalite boru hatları (görsel, video anlama)
Alternatifleri değerlendirmek gereken senaryolar:
- En zorlu çok dosyalı refactor işlerinde Opus hâlâ marjinal olarak önde
- Ticari kullanım koşulu olmayan bir lisans gereken iş yükleri
- Küçük modellerin yeterli olduğu gecikmeye duyarlı sohbet
- Belirli bir sağlayıcı bölgesi gereken regüle veri
Pratikte çoğu ekibin vardığı nokta hibrit bir model: ajanik ve uzun bağlam işlerinin büyük kısmını M3'e yönlendirip, kalitenin son birkaç puanının önemli olduğu küçük dilimi frontier kapalı modele ayırmak. Bir LLM gateway bu yönlendirmeyi çocuk oyuncağı haline getiriyor.
9. Dikkat Edilmesi Gerekenler
Birkaç önemli noktayı gözden kaçırmayalım:
- Promosyon fiyat geçici. Bütçenizi standart $0.60/$2.40 oranına göre yapın, promosyon bitince birim ekonominiz bozulmasın.
- Lisans koşulları var. Open-weights ticari kısıtlamalarla geliyor. Ticari ürüne entegre etmeden önce lisansı mutlaka inceleyin.
- Satıcı benchmarkları satıcı benchmarklarıdır. "GPT-5.5 ve Gemini 3.1 Pro'yu geride bırakıyor" iddiası MiniMax'ın kendi testlerinden. Bağımsız liderlik tabloları ve kendi değerlendirmeleriniz esas ölçüt.
- Uzun bağlam hafıza değildir. 1M token pencere yardımcı olur ama her şeyi contexte tıkmak, uzun ömürlü ajanlar için gerçek bir hafıza sisteminin yerini tutmaz. AI çağında loglama yazımızda bahsettiğimiz observability prensipleri burada da geçerli: ajan izlerini, araç çağrılarını ve kararları kayıt altına almadan uzun görevlerde hata ayıklamak imkansızlaşıyor.
10. Sonuç: Açık Kaynağın Yeni Sınırı
MiniMax M3, 2026'nın açık kaynak LLM manzarasında önemli bir dönüm noktası. 1M token bağlam penceresi, MSA ile gelen verimlilik, doğal çoklu-modalite ve kodlama/ajan alanında frontier seviyesine yakın performans, onu ciddi bir üretim adayı haline getiriyor. Açık ağırlıklı bir model olarak fiyat avantajı, onu yüksek hacimli ajanik iş yükleri için özellikle çekici kılıyor.
Ancak tek bir modele tüm iş yükünüzü bağlamak yerine hibrit bir strateji izlemek akıllıca. Maliyetin kritik olduğu işler için M3, kalitenin son birkaç puanının önemli olduğu işler için Opus veya GPT-5.5. Bir gateway üzerinden bu yönlendirmeyi kurmak hem geliştirme hızını hem de birim ekonomiyi koruyor.
M3'ü kendi iş yükünüzde denemek için en hızlı yol MiniMax platformundan bir API anahtarı almak ve OpenRouter üzerinden promosyon fiyatla test etmek. Sonuçları kendi değerlendirme setinizle karşılaştırın. Açık kaynağın bu kadar olgunlaştığı bir dönemde, tek bir modele bağlı kalmak yerine esnek kalmak en büyük rekabet avantajı.
Bu yazı MiniMax M3 modelinin kendisinin yardımıyla hazırlanmıştır. Modelin MSA mimarisi, benchmark sonuçları, fiyatlandırması ve gerçek dünya kullanım senaryoları resmi MiniMax duyurusundan ve Lushbinary geliştirici kılavuzundan derlenmiştir.
Efe Hüseyin Özkan
Yazılım Mühendisi & AI Geliştirici
Yapay zeka sistemleri, full-stack geliştirme ve ölçeklenebilir ürün mimarisi üzerine çalışıyor. Daha fazla teknik yazı için blogu takip edebilirsiniz.